自作セグメント木ライブラリ の使い方についての自分用のメモです. AtCoder Library にセグメント木はありますが, それができる前から使っていたものなので…
関連
使用法
値の型を DAT, 更新演算の型を OP とする.
基本のセグメント木
作成
auto st = make_seg_tree(unit_dat, add, init_vec);
- unit_dat は,加法単位元
- add には,加法の演算を行う関数を指定する. 関数ポインタ,クロージャ,関数オブジェクトが使える.
- init_vec は初期ベクトル
初期ベクトル設定は,分けても良い:
auto st = make_seg_tree(unit_dat, add);
st.set_data(init_vec);
値の代入 (1点)
st.set_single(i, x);
# または
st.rs(i) = x;
$i$ 番目の値として $x$ を設定する.
rs は,reference for substitution のつもり. これは,STSubst なるオブジェクトを作成して返す. STSubst オブジェクトには,代入演算子 = が再定義してあって,セグメント木の該当部分を更新するようになっている.
値の取得 (1点)
st.at(i);
$i$ 番目の値を取得する.
値の取得 (範囲)
DAT x = st.query(il, ir);
$il$ 以上 $ir$ 未満の値に add を適用した結果を返す.
遅延セグメント木
関数
3つの関数を指定する.
- add は加法. $\verb!DAT! \times \verb!DAT! \to \verb!DAT!$
- comp は更新演算の合成. $\verb!OP! \times \verb!OP! \to \verb!OP!$. comp(f, g) は,$f \circ g$ を表す.
- apply は更新演算の適用.$\verb!OP! \times \verb!DAT! \to \verb!DAT!$.
当然,apply と add の順序交換ができる必要がある.つまり,以下が成り立つ必要がある.
- $\text{apply}(f, \text{add}(x, y)) = \text{add}(\text{apply}(f, x), \text{apply}(f, y))$
作成
auto st = make_seg_tree_lazy(unit_dat, unit_op, add, comp, apply, init_vec);
ここで,unit_dat は,(DAT, add) の単位元,unit_op は,(OP, comp) の単位元である.
分けても良い:
auto st = make_seg_tree_lazy(unit_dat, unit_op, add, comp, apply);
st.set_data(init_vec);
値の代入 (1点)
st.set_single(i, x);
# または
st.rs(i) = x;
$i$ 番目の値として $x$ を設定する.これは代入であって,OP とは関係無いことに注意.
値の更新 (範囲)
st.update(il, ir, f);
半開区間 [il, ir) の各値 x を,apply(f, x) で更新する.
値の取得 (1点)
st.at(i);
$i$ 番目の値を取得する.
値の取得 (範囲)
DAT x = st.query(il, ir);
$il$ 以上 $ir$ 未満の値に add を適用した結果を返す.
設定例
1点更新,区間和取得
auto st = make_seg_tree(0LL, plus<ll>());
1点更新,区間最小値取得
auto st = make_seg_tree(LLONG_MAX, [](ll x, ll y) { return min(x, y); });
std::min は,オーバーロードがあるので,そのまま名前で渡すわけにはいかない.
区間加算,区間最小値取得
ll big = (1e18 など適当に大きな値);
auto mymin = [](ll x, ll y) -> ll { return min(x, y); };
auto st = make_seg_tree_lazy(big, 0LL, mymin, plus<ll>(), plus<ll>());
- apply と add は自然に順序交換ができる.
- 単位元を LLONG_MAX にすると,たいていオーバーフローする.
区間代入,区間最小値取得
代入する値は optional<ll> で表す.
nullptr が「何もしない」ことをあらわし,単位元となる.
using OP = optional<ll>;
ll big = (1e18 や LLONG_MAX など適当に大きな値);
auto mymin = [](ll x, ll y) -> ll { return min(x, y); };
auto comp = [](OP f, OP g) -> OP { return f ? f : g; };
auto appl = [](OP f, ll x) -> ll { return f ? *f : x; };
auto st = make_seg_tree_lazy(big, OP(), mymin, comp, appl);
区間代入,区間和取得
何も考えないと,add と apply の順序交換ができない. そこで, DAT として,long long の対をとり, 左に和を保持し,右には区間の長さを保持する. 右側は最初に設定したあとは変更されない. 加法演算としては,$\text{add}((v_1, l_1), (v_2, l_2)) = (v_1 + v_2, l_1 + l_2)$ を 用いる. 更新演算適用は,長さ $l$ の区間に一斉に $f$ を代入することになるので, 結果は $fl$ となる.ただし,$f$ が nullptr の時は,なにもしない.
using DAT = pair<ll, ll>;
using OP = optional<ll>;
auto add = [](DAT x, DAT y) -> DAT { return DAT(x.first + y.first, x.second + y.second); };
auto comp = [](OP f, OP g) -> OP { return f ? f : g; };
auto appl = [](OP f, DAT x) -> DAT { return f ? DAT(*f * x.second, x.second) : x; };
auto dat_init = vector<DAT>();
REP(i, 0, init_vec.size()) dat_init.emplace_back(init_vec[i], 1);
auto st = make_seg_tree_lazy(DAT(), OP(), add, comp, appl, dat_init);
区間加算,1点取得
上の区間加算・区間最小値取得で流用できる.Fp のような最小値を取れない場合には, 区間加算・区間和代入で代用しても良いが,区間の長さをとったりして面倒である. どうせモノイド計算は使わないので,次のように割り切る手もある. この場合,長さ2以上の区間に対する値は正しくない (が使わないので気にしない).
auto st = make_seg_tree_lazy(Fp(0), Fp(0), plus<Fp>(), plus<Fp>(), plus<Fp>());
なお,imos法ですむ場合もある.
区間代入,1点取得
上の「区間代入,区間和取得」を使っても問題無いが,どうせモノイド計算はしないので,以下でも良い.
using DAT = ll
using OP = optional<ll>;
auto dummy_add = [](DAT x, DAT y) -> DAT { return 0; }
auto comp = [](OP f, OP g) -> OP { return f ? f : g; };
auto appl = [](OP f, DAT x) -> DAT { return f ? *f : x; };
auto st = make_seg_tree_lazy(DAT(), OP(), dummy_add, comp, appl);
等差数列 (1次式) の代入・加算,区間和取得
- DAT は,(和, 区間左端の添字,区間長).
- 単位元は,適当に (-1, -1, -1) とか決めておく.
- モノイド加法は,$(v_1, i_1, l_1) + (v_2, i_2, l_2) = (v_1 + v_2, i_1, l_1 + l_2)$.
- ただし,単位元を左・右に足すときは,特別扱いとする.
- $i_1 + l_1 = i_2$ を仮定する.単位元を足すときを除いて,そういう演算しか出てこないはず.
- OP は,$(a, b)$.
- ただし,代入・加算する値が $v = ai + b$ ($v$ は値,$i$ は添字) であるとする.
- 単位元
- 加算のときには,$(0, 0)$
- 代入のときには,適当に (INF, INF) とか決めておく.
- 合成
- 代入のときには,$f \circ g = f$.ただし,単位元は別扱い.
- 加算のときには,$(a_1, b_1) \circ (a_2, b_2) = (a_1 + a_2, b_1 + b_2)$
- apply
- 下では,$w := 2(ai + b) + a(l - 1))l/2$ とする.
- 代入: $\;\text{apply}((a, b), (v, i, l)) = (w, i, l)$
- $(a, b)$ が単位元のときには別扱い.
- 加算: $\;\text{apply}((a, b), (v, i, l)) = (w + v, i, l)$
二分探索
片方の端を固定して,もう片方の端を動かして, query() の返す値が,ある性質を満たす/満たさないの境界 (満たす方) を返す. 4つのメソッドが用意されており,いずれも 引数はチェック関数と固定する端の値. チェック関数は,v = query(x, y) の値を引数にして,成立/不成立 を返す:
auto check = [&](DAT v) -> bool { ...; };
-
4つのメソッドは,以下の通り.
- 名称の
l/rは,動かす方の端を示す. - 名称の
from/untilは,固定されている端からはじめて範囲を広げながら探索するときに, あるところ「から/まで」なりたつ,という気持ちを表す.
- 名称の
-
左端を固定して右端を動かすメソッド
- 右端が右にあるほど (範囲が広いほど) 成立しやすい
st.binsearch_r_from(check, x)check(st.query(x, y))が成り立つ最小の y を返す.- そのような y が無いときには,init_vec.size() + 1 を返す.
-
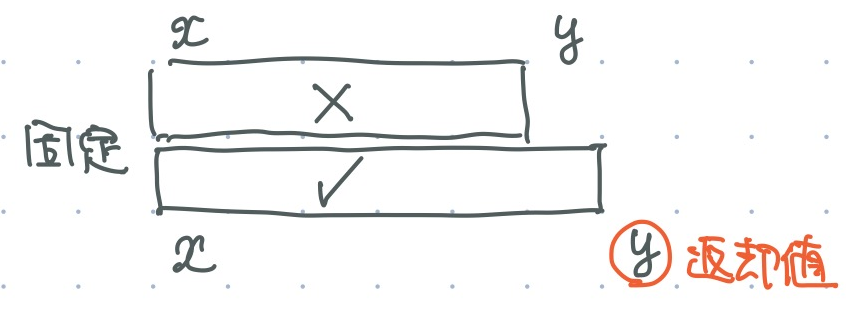
- 右端が左にあるほど (範囲が狭いほど) 成立しやすい
st.binsearch_r_until(check, x)check(st.query(x, y))が成り立つ最大の y を返す.- そのような y が無いときには,x - 1 を返す.
-
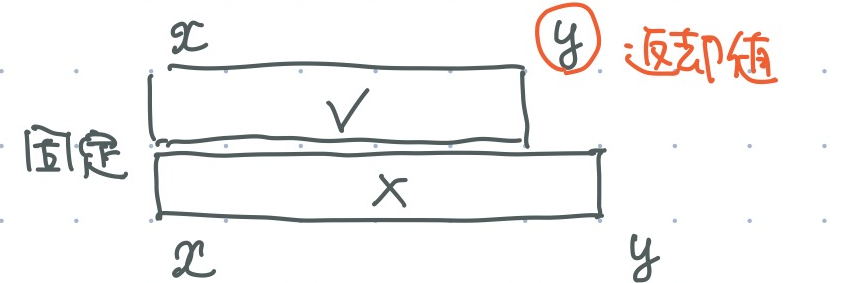
- 右端が右にあるほど (範囲が広いほど) 成立しやすい
-
右端を固定して左端を動かすメソッド
- 左端が左にあるほど (範囲が広いほど) 成立しやすい
st.binsearch_l_from(check, y)check(st.query(x, y))が成り立つ最大の x を返す.- そのような x が無いときには,-1 を返す.
-
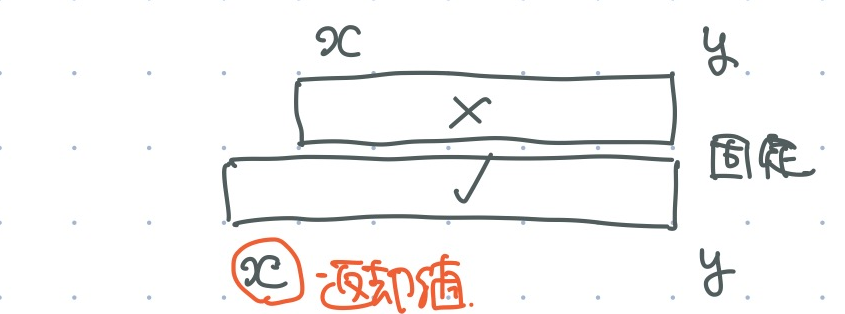
- 左端が右にあるほど (範囲が狭いほど) 成立しやすい
st.binsearch_l_until(check, y)check(st.query(x, y))が成り立つ最小の x を返す.- そのような x が無いときには,y + 1 を返す.
-
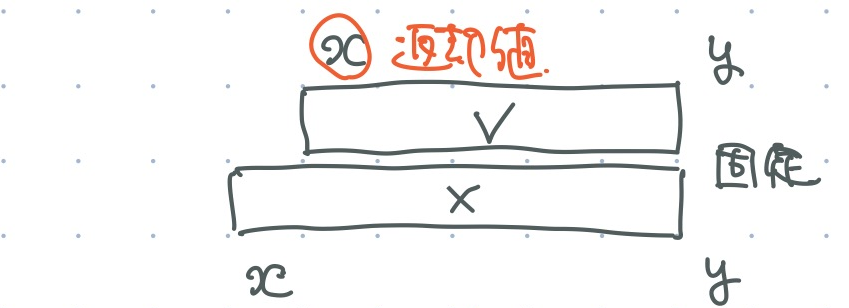
- 左端が左にあるほど (範囲が広いほど) 成立しやすい
よく使う例
$\{0, \dots, N - 1\}$ の部分集合の,$k$ 番目に小さい要素を求める.
make_seg_tree(0LL, plus<ll>()) で作られるセグメント木に,特性集合を載せておけば,
次のコードで求められる:
auto check = [&k](ll val) -> bool { return val < k; }; // 最小要素は k = 1.
// 最小要素が k = 0 になっているときには,return val <= k;.
ans = st.binsearch_r_until(check, 0);
デバッグ対応
vector<DAT> vec_view(); // 要素のベクトルを返す
セグメント木の vector
引数無しのコンストラクタが用意してあるので,
正の長さを持つ vector<SegTree<...>> を宣言することもできる.
make_seg_tree や make_seg_tree_lazy を使って,テーブル長 0 のインスタンスをひとつ作った上で,
型は decltype を利用し,初期値にそのインスタンスを指定するのが良い.
初期値を指定しないと,たとえば unit が初期化されなかったりする.
auto sgt_zero = make_seg_tree(1LL << 60, [](ll x, ll y) { return min(x, y); });
vector<decltype(sg_zero)> vec_seg(20, sgt_zero);
REP(i, 0, 20) vec2_seg[i].set_data(....);
ベクトルの要素は同じ型を持たなければならないので, 異なる加法関数などを用いる場合には,クロージャではうまくいかず, 関数ポインタを用いる必要があるかもしれない.
ノードと添字の対応
セグメント木自身を使用する際には不要だが,「セグメント木のような」構造を使用したいときに, 以下の関数が役に立つ可能性がある.
ノード $\to$ 添字の範囲
メソッド range_of_node(i) で,ノード i が表現する半開区間 [lo, hi) を取得できる.
auto [lo, hi] = st.range_of_node(i);
このメソッドと同等のことを行う関数 segtree_range_of_node(ht, i) も定義されている. ht には,セグメント木の高さを指定する.init_vec のサイズを sz とすると,次のようになる:
unsigned height = countr_zero(bit_ceil((unsigned)sz)));
auto [lo, hi] = segtree_range_of_node(height, i);
添字の範囲 $\to$ ノード
メソッド nodes_for_range(lo, hi) で,半開区間 [lo, hi) をカバーするノードを vector
auto vec = st.nodes_for_range(lo, hi);
このメソッドと同等のことを行う関数 segtree_nodes_for_range(ht, lo, hi) も定義されている. ht には,セグメント木の高さを指定する.init_vec のサイズを sz とすると,次のようになる:
unsigned height = countr_zero(bit_ceil((unsigned)sz)));
auto vec = segtree_nodes_for_range(height, lo, hi);
コードへのリンク
keywords: segtree segment tree